The premise
GENNA is my private assistant runtime. The objective is to build the closest practical version of a real-world Jarvis-style assistant: one system that can research, remember, coordinate, use voice, read documents, work across messages, and operate tools without becoming a loose chatbot with broad permissions.
For that premise to hold, GENNA has to be trusted with higher-sensitivity work. Financial data, medical records, work materials, client files, and private accounts should not be handled by a model that can directly touch every file, credential, and external tool it can reason about.
The risk is not theoretical: Replit’s AI agent deleted production data from a SaaStr database, and high-privilege personal agents have already produced real security incidents in adjacent projects.
So the project became less about adding another chat surface and more about one engineering question:
Can a personal agent stay useful over time and learn from governed memory while the runtime, not the underlying AI model, controls access to files, secrets and passwords, accounts, and external tools?
The architecture
GENNA had to match that objective from the ground up. Otherwise, a helpful assistant becomes a privileged identity with access to sensitive context, tools, accounts, and automation. That would be like handing a brilliant stranger your keys, your credit card, your contacts, and permission to act without hard rules or supervision.
It can read private material, invoke tools, spend money, send messages, run code, and persist mistakes faster than a person can review them. Prompt instructions alone cannot hold that boundary because untrusted webpages, emails, documents, and messages enter the same reasoning loop as the user’s instructions.
After researching agent security patterns, I found CaMeL in Defeating Prompt Injections by Design, a paper published by researchers from Google, Google DeepMind, and ETH Zürich. The line that mattered for GENNA was simple: untrusted data should not be able to steer what the agent does next.
”The untrusted data retrieved by the LLM can never impact the program flow.”
Debenedetti et al., Defeating Prompt Injections by Design, abstract, arXiv:2503.18813.
CaMeL turns that idea into an architecture pattern for prompt-injection-resistant agents: keep control flow and data flow separate, then make every tool call pass through explicit capability checks.
The paper reports 77% task completion with provable security in AgentDojo, compared with 84% for an undefended baseline. The benchmarked agent completed slightly fewer tasks, while the completed tasks came with a formal guarantee that policy-protected information flows were respected. For GENNA, that seven-point tradeoff is essential: lose some convenience if needed, but keep the trust boundary outside the AI model underneath.
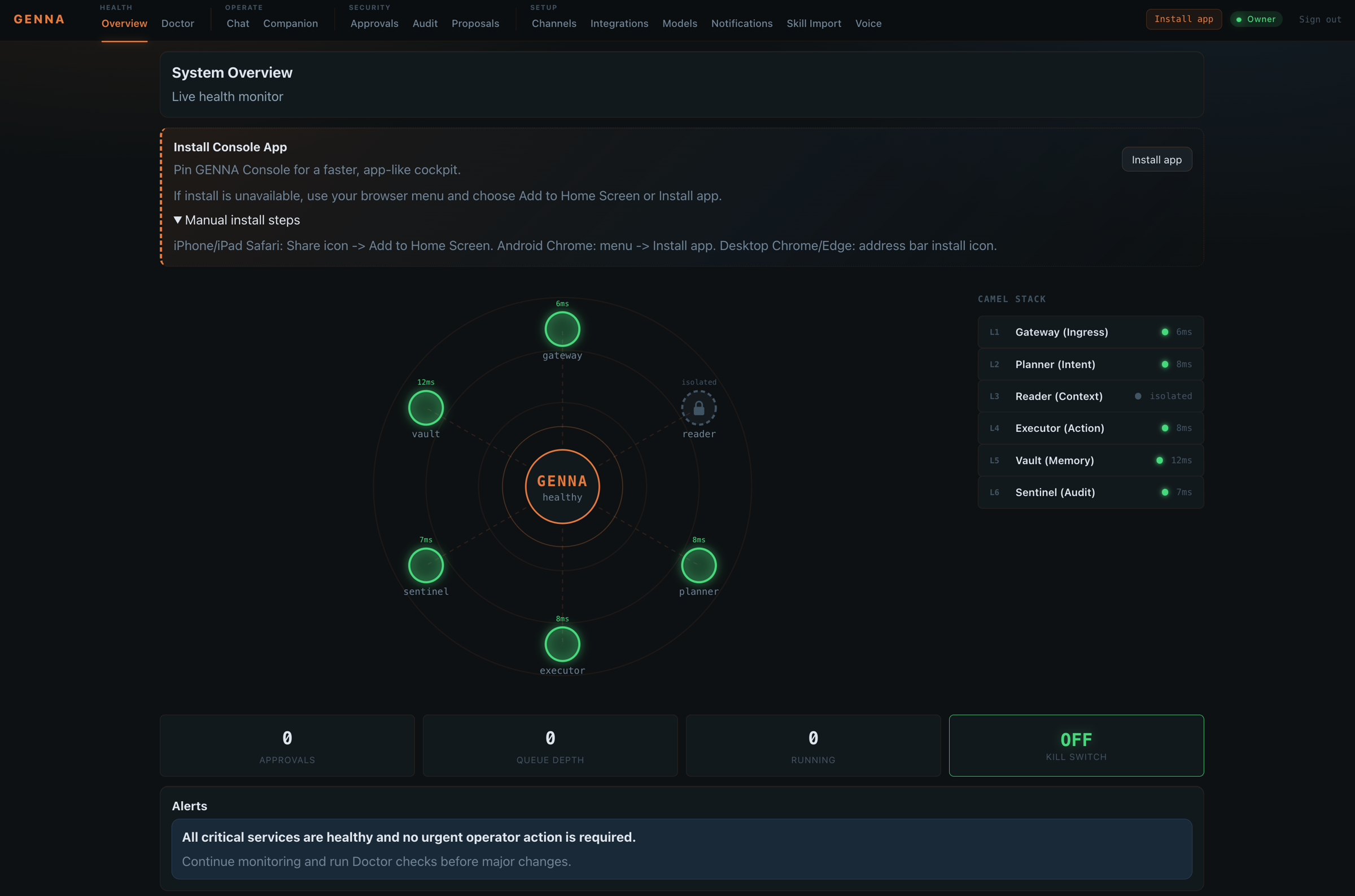
The result is a six-layer system: untrusted content is isolated, plans are separated from execution, credentials are safely stored and retrieved through Vault, and governed actions are written to Sentinel for review.
Six layers, two color-coded trust zones. The dashed quarantine boundary marks Reader; the solid arrows are the request/response pipeline; the side branches show that L4 alone reaches into L5 (secrets) and L6 (audit).
Why the boundaries matter
OpenClaw is a useful comparison point: an open-source personal AI assistant project that recently made this category visible. Its appeal is easy to understand. People want an assistant they can run on their own devices, helping with everyday work across the places life already happens: messages, files, calendars, browser tasks, voice, local apps, and small automations.
OpenClaw’s own security guide treats the risk seriously with approval rules, channel allowlists, sandboxing, and guidance to use a strong instruction-hardened model for tool-enabled agents. The same architecture category also shows why safety is hard to guarantee.
Cisco’s AI security team tested a third-party OpenClaw skill and found silent data exfiltration plus direct prompt injection, with nine findings including two critical.
SecurityWeek reported CVE-2026-25253, a token-exfiltration flaw in OpenClaw that could lead to gateway compromise and host code execution before it was patched. NVD lists CVE-2026-24763, a high-severity command-injection issue in OpenClaw’s Docker sandbox path.
CrowdStrike’s analysis describes the broader enterprise risk: prompt injection can become a facilitator for tool and data-store compromise when an agent has broad, unguarded access.
Why this matters. For a company, the gap between an interesting AI demo and something that can be connected to real systems is usually trust. GENNA addresses that gap by design: the part of the assistant that reads the messy outside world cannot reach secrets, accounts, or privileged tools, and the part that touches real systems cannot act without a capability, an approval path, and an audit entry.
GENNA is my answer to the security issues behind personal AI assistance, built for local assistants that help people work faster without giving a model unguarded authority over private data, client work, credentials, and business tools.
The runtime therefore runs as a Docker Compose-deployed set of services, with the smaller trust boundaries shown above: untrusted content is quarantined before planning, planning is separated from execution, secrets stay behind Vault, and governed actions are logged through Sentinel.
The six-layer CaMeL container isolation makes the default stack larger, but that extra structure is the point. For an assistant that may sit near private files, client work, credentials, and business tools, the defensible direction is to make authority explicit, inspectable, and limited by design. The model can propose, but the runtime decides what is allowed.
Differentiators
Design choices that matter
These choices make privacy, approvals, memory, and tool use part of the runtime itself.
Private self-hosted ownership
Designed for self-owned infrastructure, so sensitive workflows do not default to a hosted assistant path.
CaMeL container isolation
Reader, Planner, Executor, Vault, and Sentinel sit behind separate boundaries with different permissions.
Approval and audit depth
Directive checks, approval rules, and Sentinel logging make actions reviewable instead of invisible.
Governed self-extension
New capabilities converge into reviewed directives with owner approval and probation instead of open plugin sprawl.
Memory with guardrails
Personal preference memory can grow without turning every remembered detail into unlimited tool authority.
Tool integrity checks
MCP hash verification gives the runtime a way to detect tool drift before execution.
What I built
The implementation work is the system itself: service boundaries, policy checks, private assistant surfaces, tool execution, auditability, and the import path for new capabilities. The repo is a Turbo monorepo with 13 app workspaces and four shared packages. The core workspaces mirror the trust boundaries shown above, while adapters such as CalDAV and coding bridges stay separate from the runtime services that hold planning, execution, vault, and audit responsibilities.
The main build work sits in five areas:
- A Docker Compose-deployed runtime split across Gateway, Reader, Planner, Executor, Vault, Sentinel, voice, document, navigation, and scheduling services.
- A governed directive system with 74 runtime directives, GENNA’s reviewed equivalent of skills, across 16 categories including browser automation, email, filesystem operations, smart home actions, and communication workflows. New directives can be imported, generated, or community-authored, but they enter as proposals before review and approval.
- A trust-tier engine that decides how independently GENNA may act using the user, channel, requested action, approval history, and runtime risk signals.
- A self-extension path where imported or generated skills become directive proposals, then pass through owner review, probation, sandbox evidence, and Sentinel audit before normal use.
- A private assistant surface that brings request-response voice, document reading, memory, tool execution, scoped secrets, and replayable audit into one governed runtime instead of treating them as separate demos.
Trust tiers
Trust tiers are GENNA’s autonomy ladder. They answer a simple question: how independently can the assistant act in this context before it must stop for approval?
Autonomy ladder
Same assistant, different authority
Trust is evaluated from the channel, the request, and the directive. Higher tiers expand independent action, while approval gates still govern risky moves.
T0
Observe
- Independence
- No independent action
- Can do
- Answer, summarize, draft
- Approval gate
- Everything beyond observation
Reads the incoming contract
T1
Assist
- Independence
- Prepares, then asks
- Can do
- Prepare next steps
- Approval gate
- External actions
Drafts a reply for review
T2
Act
- Independence
- Can act in known paths
- Can do
- Use approved channels
- Approval gate
- Destructive actions, new contacts, financial work
Sends a routine reply in an approved channel
T3
Anticipate
- Independence
- Can act ahead of time
- Can do
- Work ahead under SOPs
- Approval gate
- Critical security and financial actions
Schedules the follow-up before being asked
Trust changes with behavior
GENNA adjusts independent action from runtime evidence. Repeated approved work can reduce how often it must pause for review; risk signals can narrow that independence before action. Channels apply their own ceiling on top, set by the trust flow above.
What GENNA notices
- Recent approvals and denials
- Channel in use (channels carry ceilings)
- Sentinel warnings flagged in the last window
How trust changes
- Approved patterns can widen autonomy gradually
- Risk signals can narrow autonomy before the next step
- Every change is recorded with a reason
Effective trust is calculated from the user, the channel, and the requested action. Inbound email starts at T0 because it carries untrusted content. Owner-controlled surfaces such as cockpit or terminal access can reach T3. Risk signals can narrow independence again: a user demotion request, Sentinel anomaly, extended inactivity, repeated denials, or approval-fatigue patterns can move the system back toward T0.
Meeting preparation makes the idea easier to see. The same calendar, message, or document capability can exist across tiers; the tier changes whether GENNA can act independently or must stop for approval.
At lower trust, it may summarize context, prepare a draft, or ask for confirmation. At higher trust, it may act inside known channels and approved workflows, or prepare proactively before being asked. If the action involves a new recipient, a file attachment, money, credentials, or a destructive change, approval gates still stop it before anything leaves the system.
The rule enforcement is systematic and lives in code, not in prompts.
Deployment model
Local-first is the current operating model. GENNA runs as a Docker Compose service stack on a trusted host, while Telegram, Cockpit, voice, and future companion apps act as control surfaces into that same governed runtime. A request can start from a phone or another device, but the authority stays with the machine that holds Vault, Sentinel, directives, approval gates, and audit logging.
That shape is intentionally portable. For personal use, local-first keeps files, credentials, and memory close to the owner. For a team, the same runtime can be placed on an internal server, private cloud, or dedicated sandboxed host, with phones, desktops, chat channels, and web surfaces acting as clients. Microsoft’s enterprise agent guidance describes the same operational needs: agent identity, access limits, policy enforcement, observability, and a way to stop unsafe behavior.
For heavier workloads, the same model can use a dedicated GPU host or private cloud worker. The important point is not the vendor; it is the boundary. Extra compute may help with model inference, voice, research, or document processing, but sensitive actions still pass through the trust model before anything reaches files, accounts, secrets, or external systems.
Directives
Directives are GENNA’s governed equivalent of agent skills, tools, or plugin capabilities. The runtime currently loads 74 directives across 16 categories, from browser automation and email to smart home and filesystem operations.
Each directive is a contract for one capability: what it can call, which parameters it accepts, which channels may use it, how often it can run, what risk level it carries, which trust tier is required, and when approval is needed.
Reuse follows the same governed path. Claude, Codex, and OpenClaw-style skill definitions can be translated through the Cockpit import path into directive TOML, reviewed as a diff, scanned, saved under probation, and promoted only after sandbox evidence. The runtime still executes directives, not side-loaded plugins.
Self-extension uses that directive path. When GENNA detects a capability gap, or when the owner imports a new skill, the system creates a proposal instead of quietly installing a plugin. The owner can review, edit, approve, or reject it in Cockpit. Approved proposals start in probation, so early executions still require approval and leave Sentinel audit evidence before the directive can be promoted for normal use.
Working scope
Today, the runtime includes request-response voice through STT/TTS, governed self-extension through directive proposals, and audited tool execution through Sentinel. The working scope is to keep expanding assistant breadth while preserving the trust model: richer voice orchestration, more workflow coverage, and smoother tool use all have to pass through approval, probation, and audit controls.
The project is currently internal and private. I am stabilizing the runtime, documentation, and security model before deciding what can be shared more broadly. I can discuss the architecture, selected implementation details, or a guided walkthrough on request.